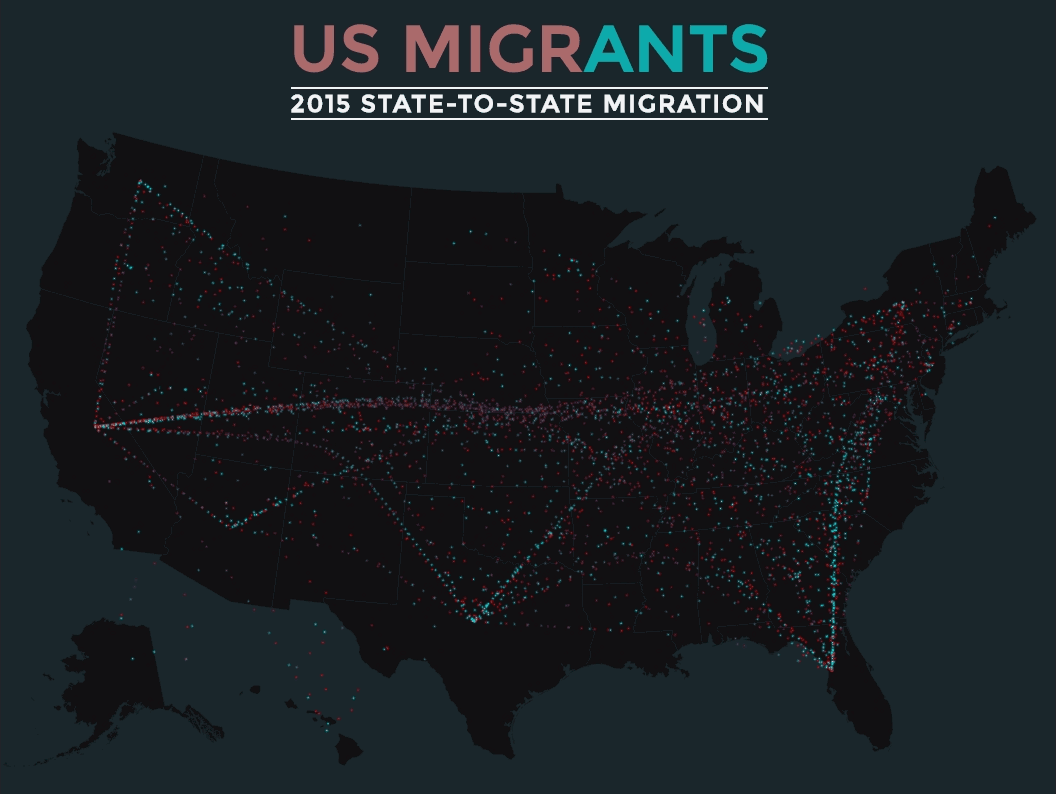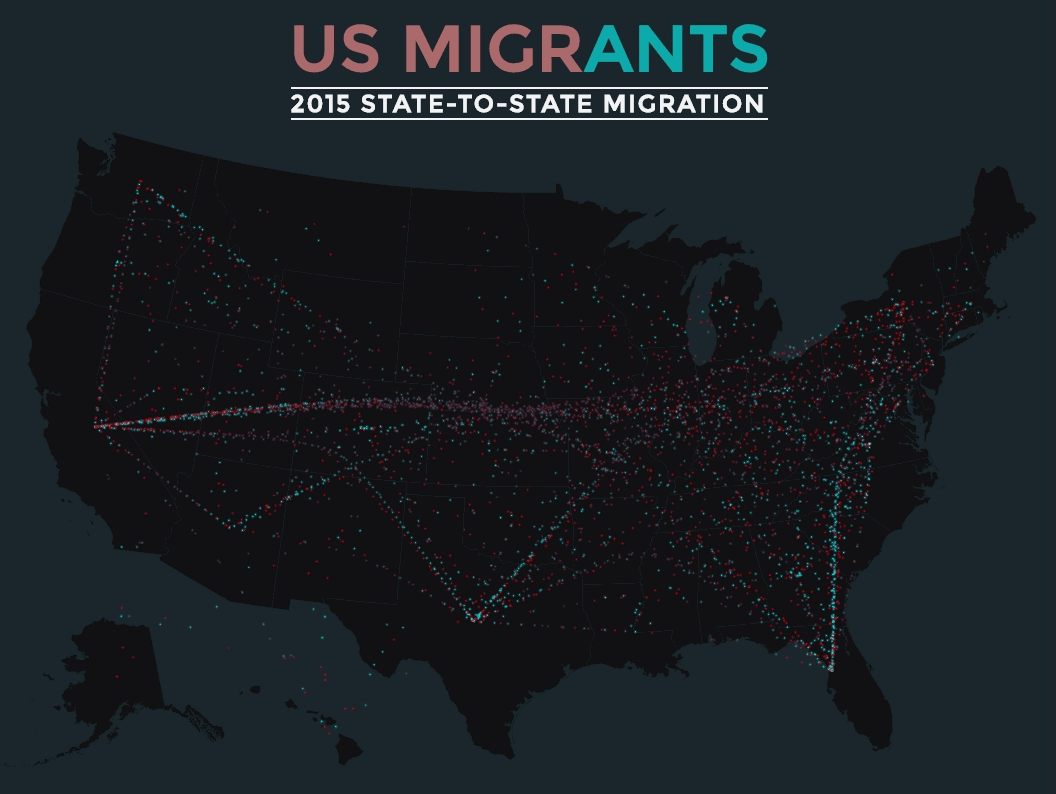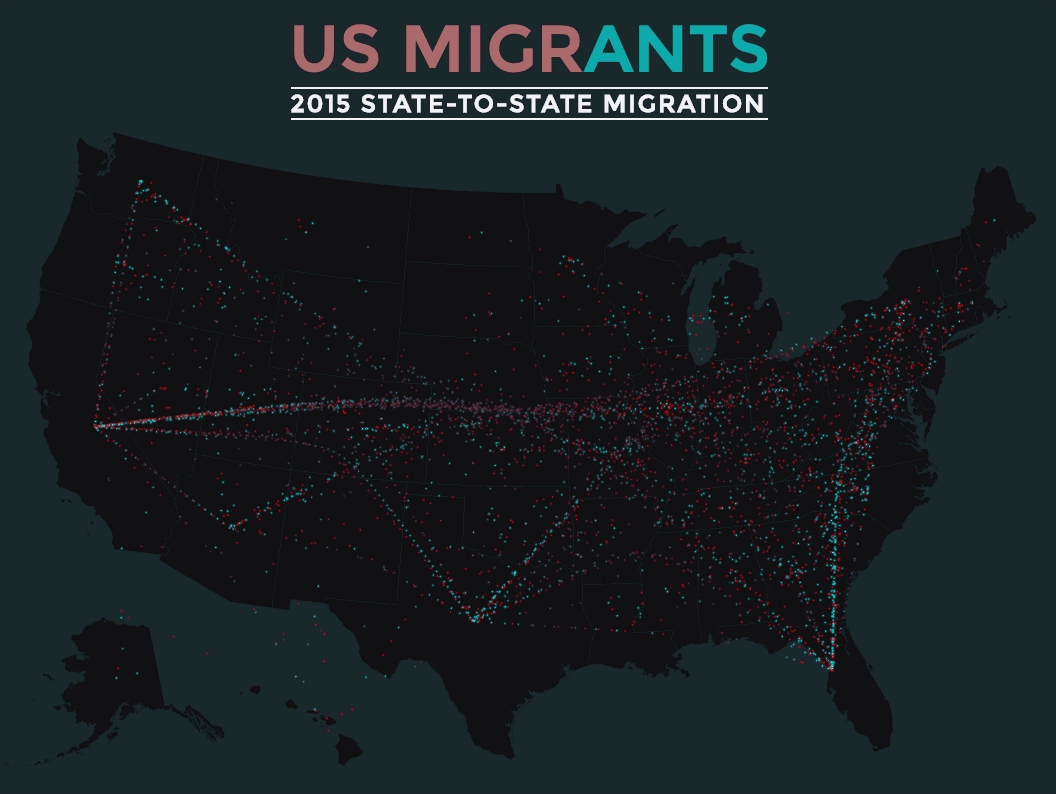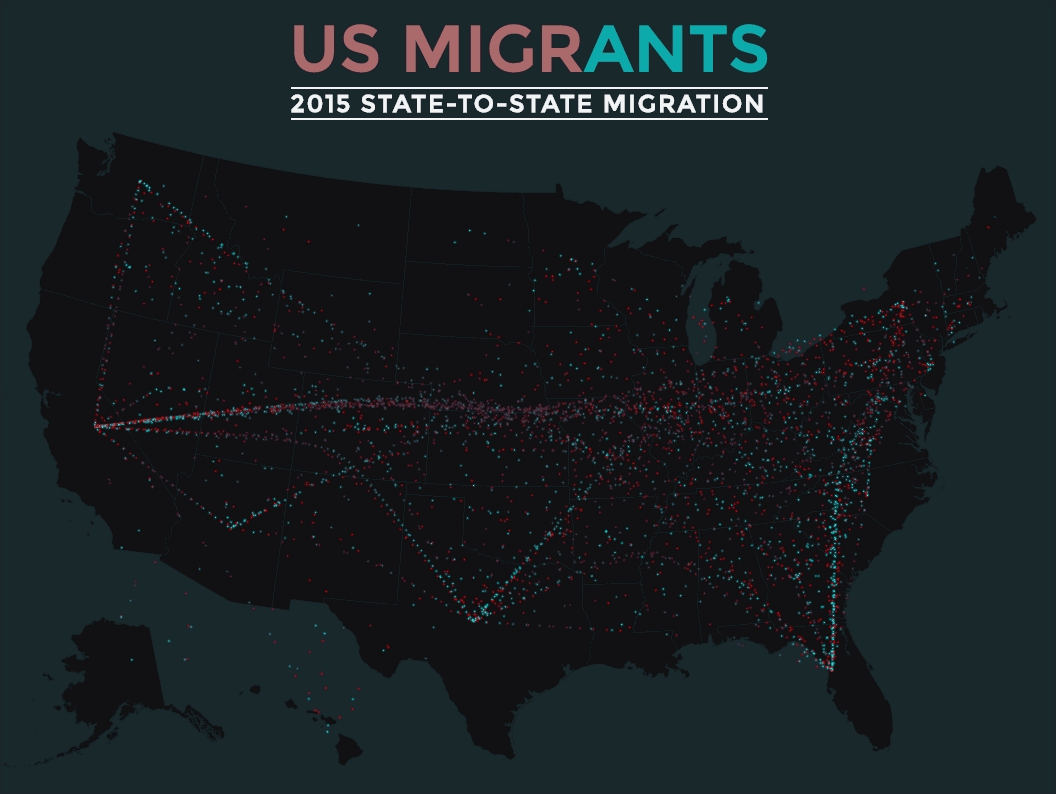
We combined storytelling, 3D mapping, and data about the hundreds of neighbourhoods in Edmonton to create “This is Edmonton”.

The Paradox of Brilliance
It seems that the amount of intelligence needed to understand an idea is inversely proportional to its brilliance. My first conjecture: great ideas are grokkable, marginal ideas are not.
In this second part of the series, we explore how to be more effective in your visualizations. In this context, we defined effectiveness as a combination of clarity and engagement.
This is part one of a two-part series on building effective visualizations. In this post, we take a shallow dive into evaluating existing visualizations. In the next post, we’ll dive a little deeper as we explore techniques on how to improve them.
In visualization we have a vehicle capable of more than just communicating numbers.
If you aspire to be a data scientist, you’re really aspiring to be a data wrangler. You see, 80% of your working hours will be spent wrangling the data. That’s on average. On some projects, you will spend more than 100% of your “working” hours with your lasso. I hope you enjoy that sort of thing.
If you aspire to be a data scientist, you’re really aspiring to be a data wrangler. You see, 80% of your working hours will be spent wrangling the data. That’s on average. On some projects, you will spend more than 100% of your “working” hours with your lasso. I hope you enjoy that sort of thing.